:quality(75)/2.blogs.elcomercio.pe/service/img/expresiongenetica/autor.jpg)
Nobel de Química 2015: ¿Cómo se protege la información genética?
Nuestro cuerpo está compuesto por unos 37,2 billones de células que se originaron a partir de una sola al momento de la fecundación. Dentro de cada una de nuestras células tenemos un poco más de dos metros de ADN que está dividido en 46 cromosomas (23 de tu padre y 23 de tu madre).
El ADN está formado por cuatro componentes: Adenina (A), Timina (T), Guanina (G) y Citosina (C), que forman una larga cadena doble (A se empareja con T y G con C, formando pares de bases) con una secuencia determinada. Esta secuencia (…CGTATGCTAGATCAT…) almacena información de forma codificada —información genética— que nos hacen lo que somos: rubios, morenos, crespos, chatos, etc. Son nada menos que 6400 millones de pares de base (pb) de información —la mitad de papá y la mitad de mamá— contenida en cada una de nuestras células.
Pero volvamos en el tiempo al momento en que uno de los millones de espermatozoides de nuestro padre alcanzó el óvulo de nuestra madre. Producto de esta fusión nace una célula: el cigoto. Al cabo de unas horas, la célula se divide en dos. La secuencia del ADN tuvo que copiarse íntegramente y sin ningún tipo de error para que las células resultantes posean la misma información genética que la original. Unas horas después, las células nuevamente se dividen. Ahora son cuatro. Una semana después ya son 128 células… Y así este proceso continua a lo largo de nuestra vida.
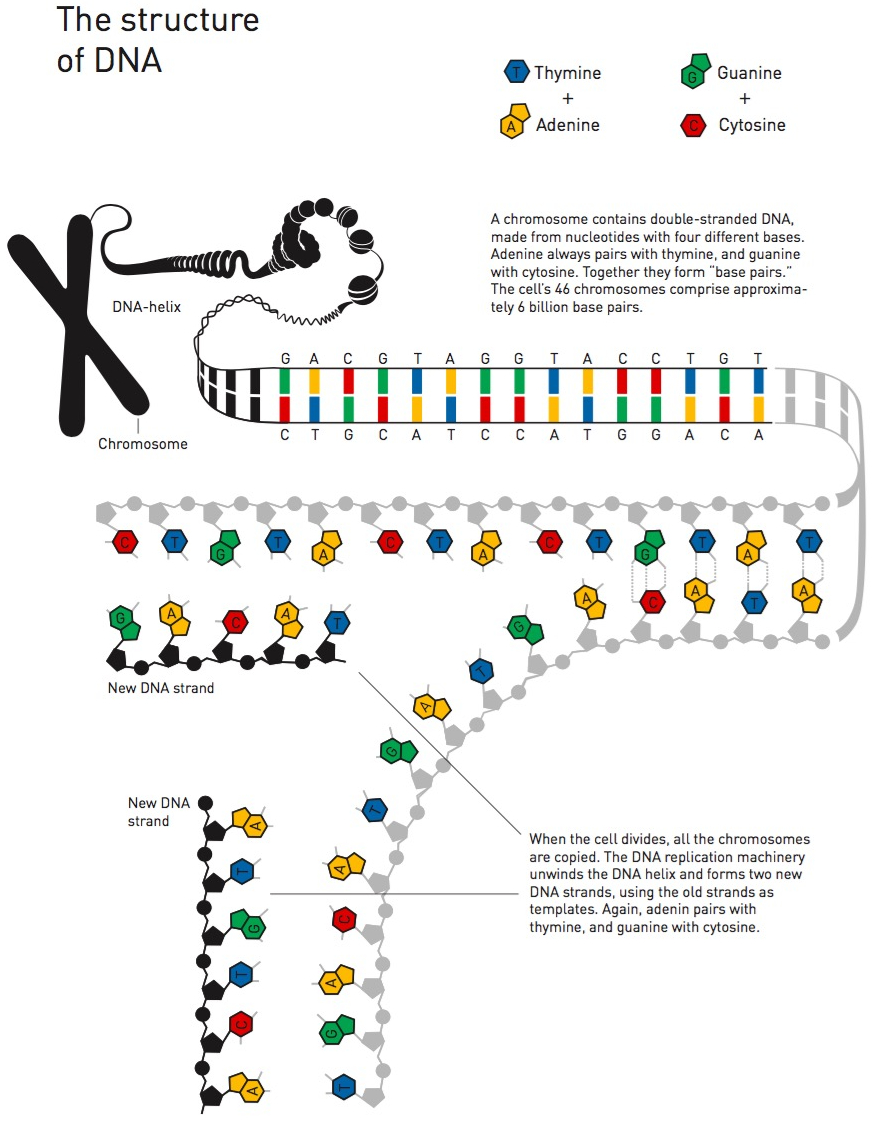
Estructura y replicación del ADN. Fuente: Nobel Prize.
Hoy, 7 de octubre de 2015, sea cual sea tu edad, tus células se han dividido miles de millones de veces. No obstante, la información genética que poseen es casi idéntica a la que se encontraba originalmente en el cigoto. Esto, desde el punto de vista químico, es imposible.
Imagínate copiar un texto de 6.400.000.000 caracteres, letra por letra y en unas pocas horas. Luego, a partir del texto copiado, repetir el proceso… Cuando compares la copia número un millón con la original, verás que se han ido acumulando una serie de errores a lo largo de todo el proceso. Esto, para una célula, sería imperdonable. Podría derivar en un cáncer, el fallo de un órgano o la muerte de la célula.
Por otro lado, las células están expuestas a radiación UV proveniente del sol, compuestos químicos tóxicos (humo del cigarro, del tubo de escape de los buses viejos, de las fábricas y fundidoras, etc.) y moléculas reactivas (radicales libres, especies reactivas del oxígeno, etc.) que tienen la capacidad de dañar el ADN, alterando su secuencia.
A pesar de todo, nuestra información genética se mantiene intacta… ¿Cómo es esto posible?
Precisamente, los ganadores del Nobel de Química de hoy: el médico sueco Tomas Lindahl, el bioquímico estadounidense Paul Modrich y el biólogo molecular turco Aziz Sancar, recibieron este prestigioso reconocimiento porque describieron el mecanismo de reparación del ADN a nivel molecular, un proceso clave para salvaguardar la información genética. No solo eso. Sus trabajos han contribuido con el entendimiento de las causas del cáncer y envejecimiento.

Es cierto que la evolución requiere de pequeños cambios en el ADN (mutaciones) para poder generar la variabilidad sobre la cual actúa la selección natural. Sin embargo, muchos cambios pueden tener efectos perjudiciales para las células que deben ser corregidos.
Bultos en el ADN
Hasta la década de 1960 no se sabía por qué el ADN era tan resiliente (capaz de soportar las perturbaciones). Lo que sí se sabía era que la radiación UV provocaba una reacción indeseada en el ADN: la unión de dos timinas (T) adyacentes [ver imagen]. Estos dímeros de timina forman una especie de bulto en el ADN que impedían su replicación, afectando así la viabilidad de las células.
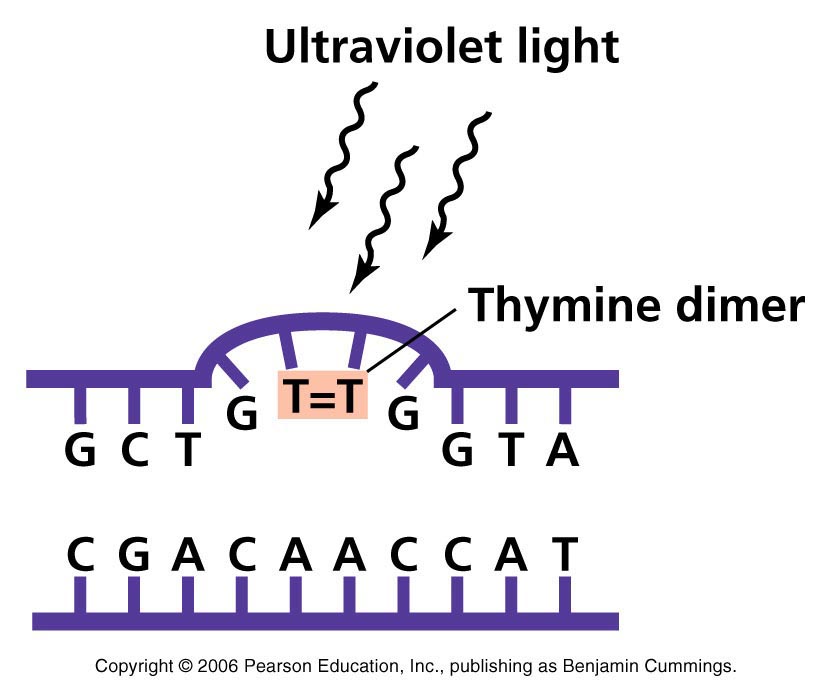
Sin embargo, un científico estadounidense llamado Stanley Rupert reportó que la luz visible era capaz de corregir esos errores en el ADN causados por la luz UV. Rupert sospechaba que era una enzima la responsable de reparar esos errores y la llamo fotoliasa. Esta fue la primera vez que se demostró que existía un mecanismo de reparación del ADN.
Fue en este momento en que un joven investigador de origen turco, llamado Aziz Sancar, llega al laboratorio de Rupert a hacer su doctorado. Su trabajo fue describir el gen que codifica la fotoliasa. Lo consiguió en 1978 y obtuvo el grado, pero dejó de lado esta investigación por seis años.
Paralelamente, se descubría otro mecanismo por el cual se reparaban los dímeros de timina que no requería de luz. Poco a poco se hallaron los genes que codificaban la enzima responsable de remover los bultos en el ADN causados por la radiación UV. Sancar —ahora en la Universidad de Yale— logró purificar las proteínas (UvrA, UvrB y UvrC) que conformaban esta maquinaria de reparación y describió cómo funcionaba.
Básicamente lo que hacía el complejo UvrABC era identificar los dímeros de timina, extraer una porción de 12 o 13 nucleótidos que contenía el bulto y luego reparar el hueco usando como molde la secuencia complementaria correcta.
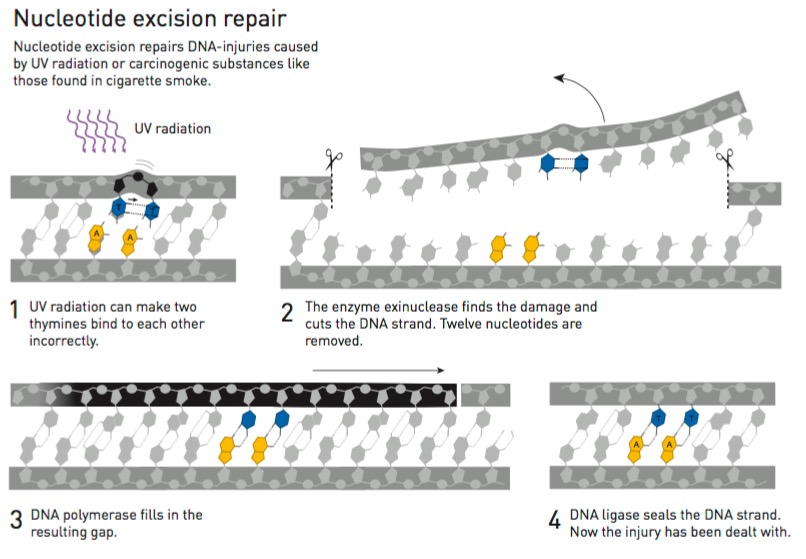
Reparación por escición de nucleótidos (NER). Fuente: Nobel Prize.
Cambio de bases
Por ese entonces, Tomas Lindahl demostraba que, en contra de lo que uno esperaría, el ADN era muy estable químicamente. Al modificar la estructura química de los nucleótidos se dio con la sorpresa que estos eran corregidos por las células.
Un cambio en la estructura de una base nitrogenada puede provocar un cambio en la secuencia de ADN. Por ejemplo, cuando a la citosina (C) se le quita un grupo amino (NH2) se convierte en uracilo (U). Mientras que la citosina se empareja con la guanina (C:G), el uracilo se empareja con la Adenina (U:A). Esto provoca un cambio en la secuencia del ADN que altera la información genética.
Lindahl descubrió en una bacteria a la enzima responsable de convertir el uracilo nuevamente en citosina y, de esta manera, corregir cualquier error que se pudiera generar. Este trabajo fue publicado en 1974 y, a partir de entonces, dedicó su vida a investigar todas las enzimas que se encargaban de reemplazar al nucleótido modificado, tanto en bacterias como en células humanas.
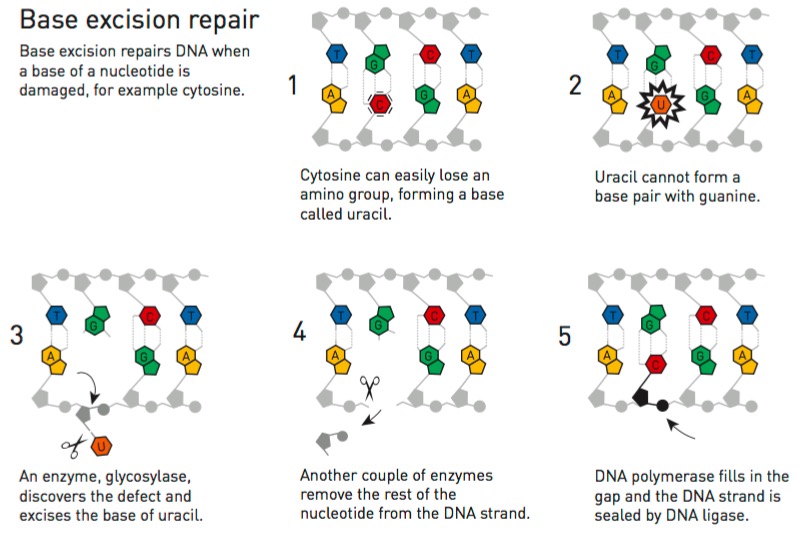
Reparación por escición de base (BER). Fuente: Nobel Prize.
Malos emparejamientos
Si bien contamos con mecanismos que nos permiten reparar errores en la estructura del ADN (bultos) o en los nucleótidos (cambios en las bases nitrogenadas), la replicación de ADN trae consigo otros errores. Recuerda que el ADN de 6400 millones de nucleótidos debe copiarse en pocas horas. La velocidad máxima de replicación es de 1000 nucleótidos por segundo. Esta rapidez podría generar errores, por ejemplo, que A se empareje con C en vez que con T, o C se empareje con T en vez que con G. A estos errores se les llama “missmatch” o malos emparejamientos.
Estos errores son muy poco frecuentes. La maquinaria de replicación del ADN es sumamente precisa (sólo un error cada millón a 100 millones de nucleótidos). Sin embargo, como el genoma es tan largo y las células se dividen tantas veces, los errores —así sean poco frecuentes— son significativos.
Fue así que Paul Modrich estudió en profundidad cómo hacen las células para reparar estos malos emparejamientos durante la década de 1980. El quid del asunto es saber cuál de las bases mal emparejadas es la correcta. Para ello descubrió que las cadenas de ADN originales van incorporando unas “etiquetas” en su estructura a través de un proceso conocido como metilación. Entonces, cuando el ADN se va copiando, la base mal emparejada es la que no tiene el grupo metilo (la etiqueta).
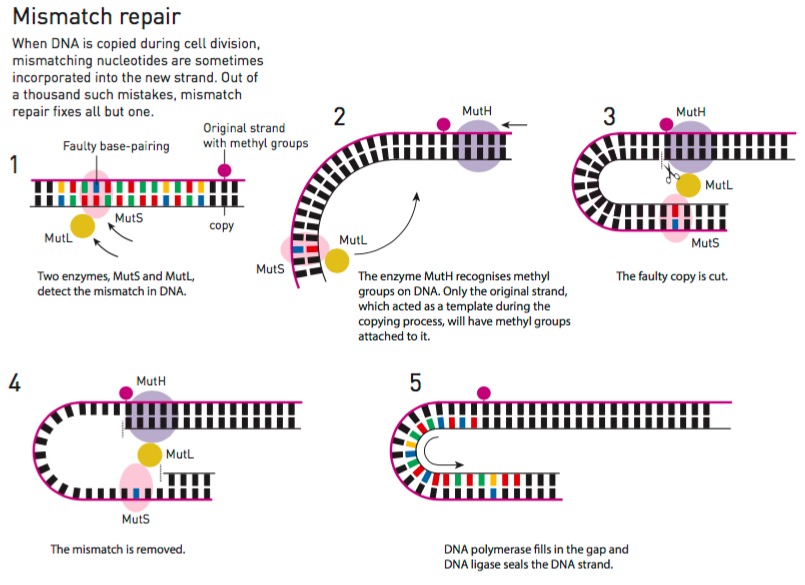
Reparación de malos emparejamientos. Fuente: Nobel Prize.
Estos tres mecanismos de reparación del ADN son la clave para mantener la información genética a lo largo de nuestra vida. Cualquier error que no sea corregido podría desencadenar en un cáncer o la muerte de la célula.
Referencia:
MLA style: “The Nobel Prize in Chemistry 2015 – Advanced Information“. Nobelprize.org. Nobel Media AB 2014. Web. 7 Oct 2015.